Meta launches new AI chatbot features: actively sending messages to improve interactive experience
1883
English
Deepseek announced the product for the second day of the Open Source Week, the first open source EP communication library for MoE models, supporting the implementation of full-stack optimization of hybrid expert model training inference.
DeepEP is an efficient communication library designed for Hybrid Experts (MoE) and Expert Parallel (EP). It is committed to providing many-to-many GPU cores with high throughput and low latency, commonly known as MoE scheduling and combinatorial.
DeepEP not only supports low-precision operations such as FP8, but also is consistent with the group limit gating algorithm proposed by DeepSeek-V3 paper, optimizing the kernel for bandwidth forwarding of asymmetric domains, such as forwarding data from the NVLink domain to the RDMA domain. These cores have high throughput, are ideal for training and inference pre-filling tasks, and can control the number of stream processors.
For latency-sensitive inference coding tasks, DeepEP also includes a set of low-latency kernels that utilize pure RDMA to minimize latency. In addition, DeepEP also introduces a hook-based communication-computing overlap method that does not occupy any stream processor resources.
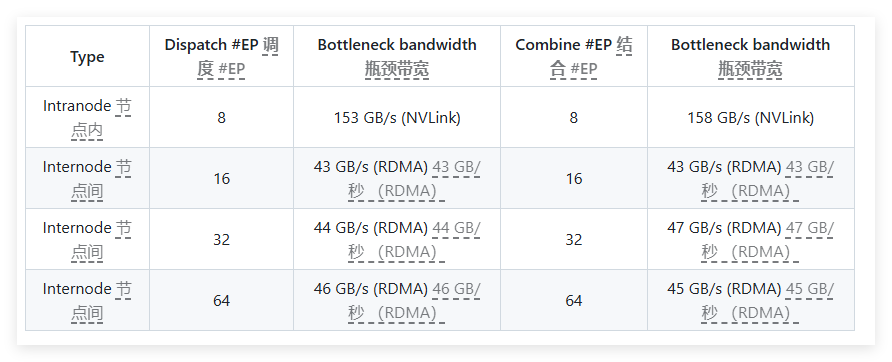
In performance testing, DeepEP conducted multiple tests on the H800 and CX7InfiniBand400Gb/s RDMA network cards. Tests show that normal kernels perform excellently in internal and cross-node bandwidth, while low-latency kernels achieve the expected results in both latency and bandwidth. Specifically, the low-latency core has a latency of 163 microseconds and a bandwidth of 46GB/s when processing 8 experts.
DeepEP is well tested and is primarily compatible with the InfiniBand network, but it also theoretically supports running on Convergent Ethernet (RoCE). To prevent interference between different traffic types, it is recommended to isolate traffic in different virtual channels to ensure that normal and low-latency cores do not affect each other.
DeepEP is an important tool for providing efficient communication solutions for hybrid expert models, with significant features such as optimized performance, reduced latency and flexible configuration.
Project entrance: https://x.com/deepseek_ai/status/1894211757604049133