Meta推AI聊天機器人新功能:主動發送消息提升互動體驗
1904
中文(繁體)
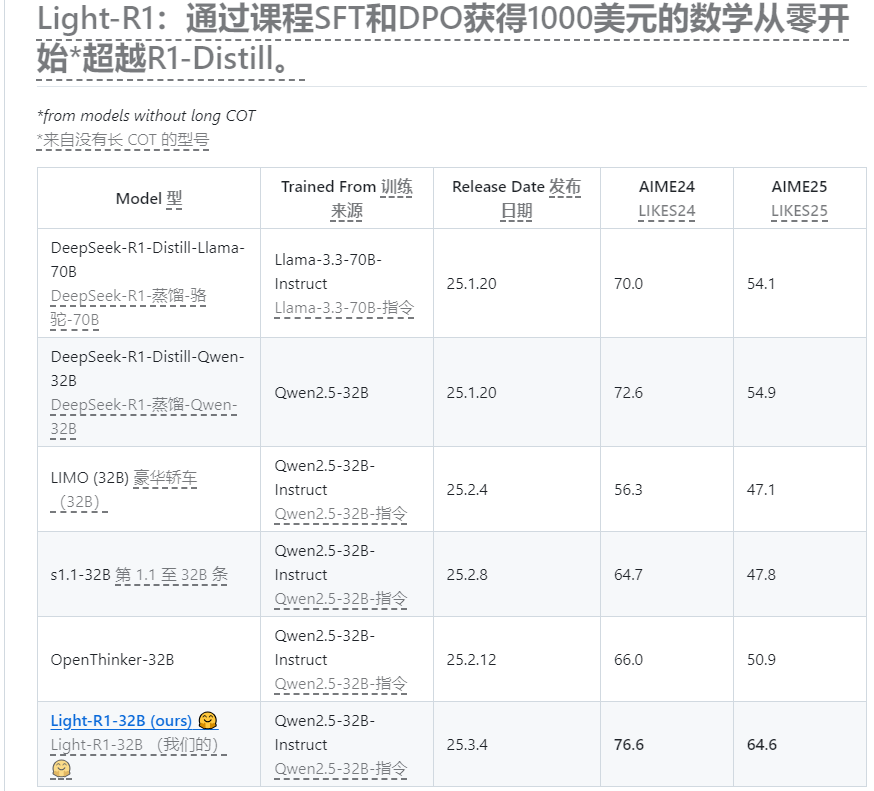
2025年3月6日,一款名為**Light-R1-32B** 的全新語言模型正式亮相。這款基於**Qwen2.5-32B-Instruct** 模型打造的數學解題利器,經過特別訓練,以其卓越的數學解題能力、低廉的訓練成本以及可複現性,成為人工智能領域的一大亮點。開發團隊xAI表示,Light-R1-32B不僅在性能上超越同類模型,還為學術研究和實際應用提供了極具價值的參考。
卓越的數學解題能力
Light-R1-32B 的核心優勢在於其出色的數學解題表現。在**AIME24** 和**AIME25** 等權威數學競賽測試中,該模型展現了比**DeepSeek-R1-Distill-Qwen-32B** 更優異的成績。更令人矚目的是,這一成果是在“從零開始”訓練的基礎上取得的,即使用不具備長鏈思維能力的初始模型,通過獨特的方法逐步提升至當前水平。這一突破證明了Light-R1-32B在復雜推理任務中的巨大潛力。
低成本與可複現性並存
在人工智能領域,模型訓練往往伴隨著高昂的成本。然而,Light-R1-32B打破了這一慣例,其訓練費用僅約為**1000美元**,大幅降低了開發門檻。更重要的是,開發團隊公開了所有訓練數據、代碼和訓練流程。這種透明度不僅便於其他研究者復現模型,還為進一步優化和擴展提供了堅實基礎,堪稱開源精神的典範。
創新訓練方法:課程學習與思維鏈強化
Light-R1-32B 的成功離不開其創新的訓練策略。開發團隊採用了**課程學習** 的方式,通過**監督微調(SFT)** 和**直接偏好優化(DPO)**,循序漸進地提升模型性能。尤其值得一提的是,訓練過程中特別強化了模型的**思維鏈(Chain of Thought)** 能力。通過在提示詞中強制加入**<think>** 標籤,模型被引導生成詳細的推理過程,從而顯著提升了解題的邏輯性和準確性。
數據清洗確保公平性
為確保評測結果的公正性,Light-R1-32B 在數據準備階段進行了徹底的**數據清洗**。開發團隊剔除了可能造成數據污染的樣本,避免了訓練數據與測試數據的交叉影響。這一嚴謹的態度進一步增強了模型在實際應用中的可信度。
未來展望
Light-R1-32B 的發布不僅為數學問題求解領域注入了一股新風,也為人工智能的低成本開發樹立了標杆。無論是學術研究者還是行業從業者,都可以通過復現和優化這一模型,探索更多可能性。 xAI表示,未來將繼續完善Light-R1-32B,推動其在教育、科研和工程等領域的廣泛應用。
Light-R1-32B 以其低成本、高性能和強思維鏈的特點,重新定義了數學解題模型的價值。正如其名字所示,它如同一束光芒,照亮了人工智能與數學結合的新路徑。
地址:https://github.com/Qihoo360/Light-R1