Meta推AI聊天機器人新功能:主動發送消息提升互動體驗
1883
中文(繁體)
olmOCR 是一款開源的光學字符識別(OCR)工具,旨在高效地將PDF 及其他文檔轉換為純文本,同時保留自然的閱讀順序。這款工具不僅支持普通文本的提取,還能處理表格、數學公式和手寫內容,極大地方便了用戶對文檔的處理需求。
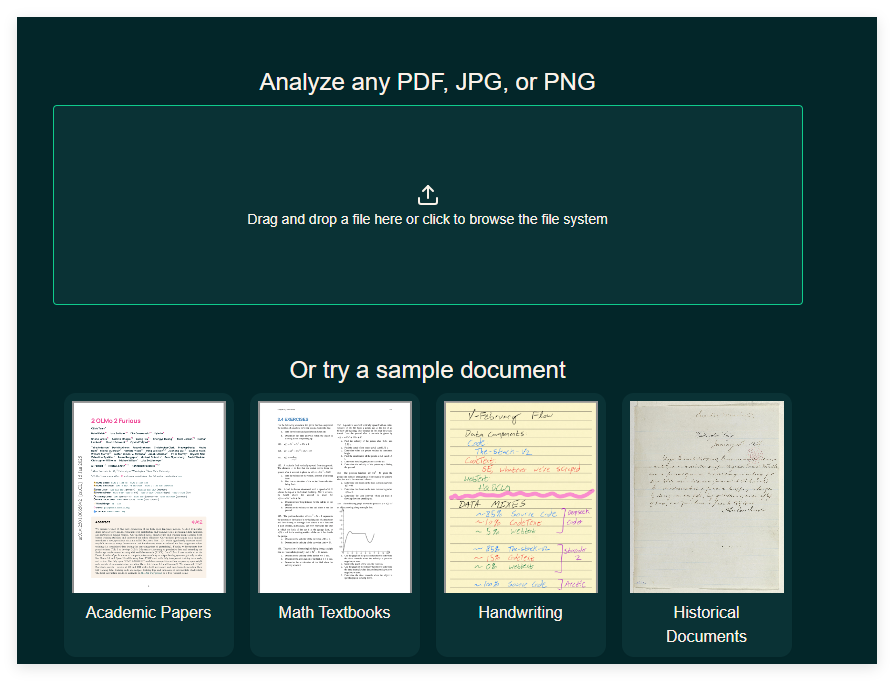
這款工具的核心優勢在於其高準確率。 olmOCR 經過大量學術論文、技術文檔及其他參考內容的訓練,採用獨特的提示技術來提高識別的準確性,並降低錯誤信息的生成。這使得用戶在使用時能獲得更為精準的轉換結果。
目前,olmOCR 的模型主要針對英語文檔進行了優化,其他語言的文檔轉換效果可能不盡如人意。用戶可以通過在線演示來嘗試該工具,並在自己的文檔上進行測試。對於需要更高處理效率的用戶,可以選擇在自己的GPU 上部署完整的olmOCR 工具包,享受高效、可擴展的文檔處理能力。
需要注意的是,在線演示會按頁面順序逐一處理文檔,而在工具包中則可以使用批量模式以實現更高的處理速度。此外,olmOCR 支持多種文件格式,包括PDF、JPG 和PNG,用戶可以根據需求選擇合適的文件進行轉換。無論是學術論文、數學教科書、手寫內容還是歷史文檔,olmOCR 都能提供有效的解決方案。
隨著數字化進程的加快,文檔的電子化已成為一種趨勢。 olmOCR 的出現為這一趨勢提供了有力的技術支持,使得用戶能夠更輕鬆地將紙質文檔轉化為可編輯的數字格式。這不僅提高了工作效率,也為信息的存儲和分享帶來了便利。
github:https://github.com/allenai/olmocr